...
- On the Desktop, double-click the Computer icon > gisdata This PC > GISData (\\file-rnassmb.rdf.rice.edu\research\FondrenGDC) (RO:) > > GDCTraining > 1_Short_Courses > > Analyzing_Spatial_Patterns.
- To create a personal copy of the tutorial data, drag the Patterns folder onto the Desktop.
- Close all windows.
...
- Click Patterns.zip above to download the tutorial data.
- Open the Downloads folder.
- Right-click Patterns.zip and select Extract All....
- In the 'Extract Compressed (Zipped) Folders' window, accept the default location into the Downloads folder and click Extract.
- Drag the unzipped unzipped Patterns folder onto your Desktop.
- Close all windows.
...
This layer provides boundaries for all of the census tracts in Harris County. For more information on census tracts, review the Introduction to Census Geographies course.
- In the Contents pane on the left, right-click the CensusTracts_MTTW_2014 layer name and select Attribute Table.
...
The Spatial Autocorrelation tool evaluates whether data is clustered, dispersed, or randomly distributed, based on both feature locations and feature values simultaneously.
...
In the top left, notice that the z-score is 39.43. In the top right, notice that any z-score larger than 2.58 has less than 1% chance of occurring randomly. In the center section is the normal distribution curve and a dotted line illustrating where the z-score for this analysis is located on that curve. It also illustrates that a positive z-score indicates that the data is clustered, while a negative z-score would indicate that the data is dispersed. Below the diagram is a helpful summary sentence, "Given the z-score of 39.43, there is a less than 1% likelihood that this clustered pattern could be the result of random chance." Because the z-score is more than an order of magnitude larger than 2.58, you will notice, in the top left, that the p-value is actually 0.00, which means there is essentially no chance that this pattern is random.
Simply knowing that the percentages of people who drove alone to work are highly clustered might not provide you with actionable knowledge, but what this result indicates is that there is a strong spatial pattern present in this data, which is worth investing the time to investigate further. If On the other hand, if the data was randomly distributed, you could stop here. Because you know your data displays strong clustering, you can now ask more interesting questions. Is it the high or low percentages of commuters driving alone that are clustered? Where are they clustered? You will see find that all of the spatial statistics tools build upon each other to answer these questions and provide additional knowledge.
...
Again, the z-score indicates that the percent of people who took public transportation to work is highly clustered. The enormous z-score of 55.84 indicates that the public transportation variable is the most highly clustered of the three. Logically, this makes sense, because we would think people living near metro stations or major bus route stops would be more likely to use them and, therefore, people taking public transportation to work would be strongly spatially clustered around those stop locations.
...
- At the top of the Geoprocessing pane, click the Back arrow button.
- Within the Analyzing Patterns toolset, click the Incremental Spatial Autocorrelation tool.
- In the upper right corner of the ‘Incremental Spatial Autocorrelation’ tool, hover over the Help ? button.
(Help)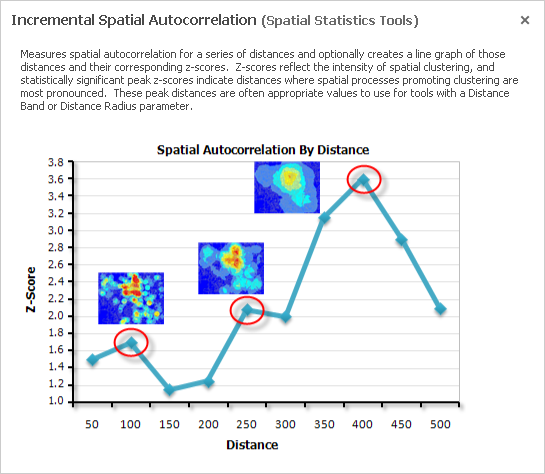
The Incremental Spatial Autocorrelation tool iterates the Spatial Autocorrelation tool using multiple distance bands and plots the corresponding z-scores at each distance. The result is a chart showing you the peak z-scores at distances where spatial clustering is most pronounced.
...
- For 'Input Features', use the drop-down menu to select the CensusTracts_MTTW_2014 layer.
- For 'Input Field', use the drop-down menu to select the Percent_CarTruckOrVan_droveAlone field.
- For 'Number of Distance Bands', type "25".
- For 'Output Report File', type "ISA_DroveAlone_25.pdf". If you click elsewhere, you will be able to see the full file path and notice that the tool will automatically locate your PDF file within your project folder.
- Click Run.
- Hover over the Completed with warnings message and click the Output Report File hyperlink.
...
- For 'Input Field', use the drop-down menu to select the Percent_CarTruckOrVan_carpooled field.
- For 'Number of Distance Bands', type "10".
- For 'Output Report File', type "ISA_Carpooled_10.pdf".
- Click Run.
- Hover over the Completed with warnings message and click the Output Report File hyperlink.
This variable displays a reverse pattern in that the significance of clustering decreases as distance increases. In fact, when the distance is greater than approximately 65,000 feet, the pattern becomes random, rather than clustered, as indicated by the yellow data points on the chart. This is the same distance at which driving alone displayed peak clustering. You could rerun the tool and set specify a beginning distance and a distance increment to determine if there is a peak distance below 40,000 feet.
...
- For 'Input Field', use the drop-down menu to select the Percent_PublicTransportation field.
- For 'Number of Distance Bands', type "10".
- For 'Output Report File', type "ISA_Transit_10.pdf".
- Click Run.
- Hover over the Completed with warnings message and click the Output Report File hyperlink.
...
- At the top of the Geoprocessing pane, click the Back arrow button.
- Within the Analyzing Patterns toolset, click the High/Low Clustering (Getis_-Ord General G) tool.
- In the upper right corner of the ‘High/Low Clustering’ tool, hover over the Help ? button.(Help)

The High/Low Clustering tool is very similar to Spatial Autocorrelation tool, except instead of telling you whether the data is clustered or dispersed, it tells you whether there are clusters of high values or clusters of low values.
Percent Commuting Alone By Car
- For 'Input Feature Class', use the drop-down menu to select the CensusTracts_MTTW_2014 layer.
- For 'Input Field', use the drop-down menu to select the Percent_CarTruckOrVan_droveAlone field.
- Check Generate Report.
- Click Run.
- Hover over the Completed with warnings message and click the Report File hyperlink.
Pay attention to the “General G Summary” table, which shows this is a “low-clusters” scenarioNotice that the z-score is negative, which indicates that areas in which a low percentage of commuters drive alone are clustered. This probably represents an inverse relationship with commuters who are carpooling or using public transit, in which we expect high percentages to be clustered.
Percent Commuting By Carpool
- For 'Input Field', use the drop-down menu to select the Percent_CarTruckOrVan_carpooled field.Check Generate Report.
- Click Run.
- Hover over the Completed with warnings message and click the Report File hyperlink.
Pay attention to the “General G Summary” table, which shows this is a “high-clusters” scenarioAs expected, this variable displays a high-clusters pattern.
Percent Commuting By Public Transportation
- For 'Input Field', use the drop-down menu to select the Percent_PublicTransportation field.Check Generate Report.
- Click Run.
- Hover over the Completed with warnings message and click the Report File hyperlink.
Pay attention to the “General G Summary” table, which shows this is a “high-clusters” scenarioThis variable also displays a high-clusters pattern, indicating that areas in which a high percentage of commuters use public transportation are clustered.
For the next set of tools, you will run them each twice: once with a polygon dataset of race by census tract and once with a point dataset .
Percent White
Optimized Hot Spot Analysis
on crime locations. The instructions for the point dataset are not yet available, but will be posted here on the wiki next week.
Percent White
- At the bottom of the Geoprocessing pane, click the Catalog tab.
- Within In the Catalog pane on the right, within the Patterns.gdb geodatabase, right-click the CensusTracts_Race_CensusTracts2014 feature class and select Add To Current New Map.
Since hot spot analysis is based on a distance threshold, it is important to get a good understanding of the spatial autocorrelation of your data as it related to distance threshold. One option is to run the incremental spatial autocorrelation on the same variable first, to help determine an appropriate distance threshold, which can then be entered in the Hot Spot Analysis tool. Another option is to use the Optimized Hot Spot Analysis tool, which will automatically run the Incremental Spatial Autocorrelation tool first in the background to select the distance threshold with the most significant?
- At the top of the Geoprocessing pane, click the Back arrow button.
- Within the Spatial Statistics toolbox, click the Mapping Clusters toolset > Optimized Hot Spot Analysis tool.
- In the upper right corner of the ‘Hot Spot Analysis’ tool, hover over the Help ? button.
- (Help)
asdf
- For 'Input Features', use the drop-down menu to select the CensusTracts_Race_2014 layer.
- For 'Output Features', type "Race_OHSA".
- For 'Analysis Field', use the drop-down menu to select the Percent_White field.
- Check Generate Report.
- ClickRun.
...
This layer also provides boundaries for all of the census tracts in Harris County, but, this time, with race data attached.
- In the Contents pane, right-click the CensusTracts_Race_2014 layer name and select Attribute Table.
The attribute table includes data on the percent of the population within each census tract of each race. For this analysis, you will study the distribution of the white population.
- Close the CensusTracts_Race_2014 table view.
Since hot spot analysis is based on a distance threshold, it is important to get a good understanding of the spatial autocorrelation of your data, as it relates to distance threshold. One option, which you will pursue, is to run the Incremental Spatial Autocorrelation tool on the same variable first, to help determine an appropriate distance threshold, which can then be entered in the Hot Spot Analysis tool. Another option is to use the Optimized Hot Spot Analysis tool, which will automatically select an optimal distance threshold for you.
Incremental Spatial Autocorrelation
- At the bottom of the Catalog pane, click the Geoprocessing tab.
- At the top of the Geoprocessing pane, click the Back arrow button.
- Within the Mapping Clusters toolsetthe Analyzing Patterns toolset, click the Cluster and Outlier Analysis (Anselin Local Morans I)Incremental Spatial Autocorrelation tool.
- For 'Input Feature ClassFeatures', use the drop-down menu to select the CensusTracts the CensuTracts_Race_2014 layer.
- For 'Input Field', use the drop-down menu to select the the Percent_White field field.
- For 'Output Features', rename the feature class from asdf to "Race_COA".
Crime Points
Optimized Hot Spot Analysis (Getis-Ord Gi*)
- In the Catalog pane on the right, within the Patterns.gdb geodatabase, right-click the Crimes_2014 feature class and select Add To New Map.
- Right-click the Freeways feature class and click Add To Current Map.
Houston crime data is reported at the block level, not the individual address level to protect confidentiality. Therefore, when the addresses are geocoded, all crimes that happened within a single block are all geocoded to the separately to the same point location in the center of the block, resulting in coincident, or overlapping points for all crimes. In order to run a hot spot analysis on this point data, we, instead, need to have a single point at each location and a value field indicating the number of crimes that occurred in that location. In our case, the address data was all run using a consistant geocoder, so we can be sure that crimes on the same block were located at exactly the same point. If, however, you were aggregating crime data points from a variety of data providers who may have used a variety of geocoding methods or if you created a community website, where residents could manually click on a location to report a crime, you would need a way of standardizing the crime locations, otherwise the number of crimes at each location might simply be 1, which would not provide for as interesting of results. Though not necessary for our dataset, you will test out the integrate tool for messier datasets.
Copy Features
The first step is to use the Collect Events tool to aggregate the data, but it is important to make a copy of the original input data before proceeding, because the Integrate tool modifies the input dataset by shifting, or standardizing, the locations of the input features.
- At the top of the Geoprocessing pane, click the Back arrow button.
- Click the Data Management Tools toolbox > Features toolset > Copy Features tool
- For 'Input Features', use the drop-down menu to select the total_Crimes layer.
- For 'Output Feature Class', rename the output feature class from to total_crimes_original.
Show how to see multiple points at same location and attribute table.
Integrate
...
- Number of Distance Bands', type "15" .
- For 'Beginning Distance', type "10000" (50000).
- For 'Output Report File', type "ISA_White_15.pdf".
- Click Run.
- Hover over the Completed with warnings message and click the Output Report File hyperlink.
Notice that the the peak threshold distance is 24,962 (54000), which you will use as the distance for your hot spot analysis.
Hot Spot Analysis
- At the top of the Geoprocessing pane, click the Back arrow button.
- Within the Spatial Statistics toolbox, click the Mapping Clusters toolset > Hot Spot Analysis (Getis-Ord GI*) tool.
- In the upper right corner of the ‘Hot Spot Analysis’ tool, hover over the Help ? button.

- For 'Input Features', use the drop-down menu to select the CensusTracts_Race_2014 layer.
- For 'Input Field', use the drop-down menu to select the Percent_White field.
- For 'Output Feature Class', rename the feature class "HSA_White".
- For 'Distance Band or Threshold Distance', type "24962".
- Click Run.
Unlike the previous tools, which only provided a table of statistics, this tool outputs a new spatial layer in your contents pane.
| Info |
|---|
If your newly added HSA_White layer changes from the default blue, white, and red symbology to a single color symbology, hover over the Undo button on the Quick Access toolbar, above the Ribbon.
If the undo step says "Symbology - Update layer renderer : HSA_White, then click the Undo button to restore the default symbology. |
Notice that there are hot spots in red, which are statistically significant clusters of high white population, along with cold spots in blue, which are statistically significant clusters of low white population. There are also areas in white, which are not statistically significant. If you are familiar with how race is distributed throughout the city, this result should not be too surprising.
Cluster and Outlier Analysis (Anselin Local Moran's I)
- At the top of the Geoprocessing pane, click the Back arrow button.
- Within the Data Management Tool toolbox, click the Feature Class toolset > Integrate tool.the Mapping Clusters toolset, click the Cluster and Outlier Analysis (Anselin Local Moran's I) tool.
- For 'Input Feature ClassFor 'Input Features', use the drop-down menu to select the total crimes layer.
A good rule of thumb for the XY tolerance is to consider the accuracy of your data. In this case, all crimes were reported by blocks and were geocoded at centers of blocks, so we could techically will set XY tolerance to 0 for the aggregation.
Collect Events
- In the Geoprocessing pane, within the Spatial Statistics Tools toolbox,click the Utilities toolset > Collect Events tool.
- Click OK.
Notice that the output from Collect Events is rendered with graduated circles reflecting the number of incidents at each point)
- Geoprocessing -> ArcToolbox -> Spatial Statistics Tools -> Mapping Clusters -> Hot Spot Analysis (Getis-Ord Gi*)
- Result:
Note that hot spot doesn’t mean high value. A has a feature with low value, but surrounding neighbors all have high value, which will cause a significantly high mean value than the global mean for this spot. It depends on the scale of the analysis.
Optimized Hot Spot Analysis (Getis-Ord Gi*)
Using Census Block Groups and total_crimes Datasets
Version 10.3 and 10.4 have “optimized hot spot analysis tool”, which automatically aggregates data first and does hot spot analysis for points data. For this tool, we will aggregate data by census block groups.
- At the top of the Geoprocessing pane, click the Back arrow button.
- Within the Spatial Statistics toolbox, click the Mapping Clusters toolset > Optimized Hot Spot Analysis tool.
- In the upper right corner of the ‘Hot Spot Analysis’ tool, hover over the Help ? button.
- (Help)
- For 'Input Features', use the drop-down menu to select the total layer.
- For 'Output Features', type "Race_OHSA".
- For 'Analysis Field', use the drop-down menu to select the Percent_White field.
- Check Generate Report.
- Click Run.
Cluster and Outlier Analysis (Anselin Local Morans I)
- At the top of the Geoprocessing pane, click the Back arrow button.
- Within the Mapping Clusters toolset, click the Cluster and Outlier Analysis (Anselin Local Morans I) tool.
Using “AggregatedTotalCrimes” dataset, which was generated during the Hot Spot Analysis.
...
- to select the CensusTracts_Race_2014 layer.
- For 'Input Field', use the drop-down menu to select the Percent_White field.
- For 'Output Features', rename the feature class "COA_White".
- Click Run.
Again, a new layer has been added to your map and you may need to undo the layer render if your census tracts are showing as a single color. The resulting high-high and low-low clusters should fairly closely match the hot and cold spots in the prior analysis and are represented in light pink and blue. The areas of low white population within a cluster of high white population are represented in dark blue and the areas of high white population within a cluster of low white population are represented in dark red. In this case, many of these outliers are on the periphery of the hot and cold spots as they transition into areas which are not significant, which makes the results less interesting. Cluster and outlier analysis is often more telling at a smaller geographic unit. For example, if you were to rerun this same analysis at the census block level, you would see individual red blocks with a high white population within a huge neighborhood of light blue with a low white population. These outliers will prompt you to pose interesting questions to try to explain them. In one neighborhood we investigated in Houston, these high-low outliers, or red blocks, corresponded to blocks with high numbers of building permits. Those two pieces of information combined present a compelling picture of gentrification. Instructions for running the analysis on the block level data will be added to this wiki next week. Because the geographic units are much smaller, calculating the results takes more time.